
관리 메뉴

Gom3rye
데이터베이스 본문
Maria DB
- 현재 접속자 확인 - select user( );
- 현재 사용 중인 데이터베이스 확인 - select database( );
- 데이터베이스 변경 - use 데이터베이스이름;
Function
- 입력 데이터를 이용해서 연산을 수행한 후 출력 값을 만들어내는 개체
- 입력 데이터를 Argument(Parameter, 매개변수, 인수, 인자 등)이라 하고 출력 값을 Return Value 라고 합니다. (프로그래밍 언어의 함수는 리턴 값이 없는 경우도 있지만, 데이터베이스의 함수는 반드시 리턴을 하고 원본을 변경하지 않는다. 데이터베이스를 수정할 수 있는 건 sql 밖에 없다.)
- 함수: 데이터 → 데이터를 수행 or → 연산을 수행해서 리턴
- 함수의 종류
- Scala Function: 데이터 단위로 연산을 수행하는 함수
- 데이터 1개를 주면 1개가 리턴되고 하나의 열을 대입하면 열에 존재하는 데이터만큼 리턴
- ex. 데이터 3개 주면 결과도 데이터 3개
- Grouping Function: 여러 개의 데이터를 묶어서 연산을 수행하는 함수
- ex. 평균 구해주세요.
- System Function: Null 관련 처리나 Type변환 등을 수행하는 함수
- ex. 결측치 나왔을 때 어떻게 처리해줄지
단일 행 함수
수치 함수
- ROUND(컬럼 이름이나 표현식, 반올림할 자릿수) - 양수를 기재하면 그 자리에서 반올림을 하고 음수를 기재하면 1의 자리부터 위로 올라간다.
- scala function이다.
- 0.5 반올림 안 하고 버리는 경우 있으니 잘 보기
select sal, round(sal, -2), floor(sal/100 + 0.5) * 100 # floor: 소수를 버리는 함수
from emp;
- MOD(컬럼 이름이나 표현식, 나눌 수): 뒤의 수로 나누어서 나머지 리턴
- ex. EMP 테이블에 사원번호(EMPNO)가 홀수인 사원의 모든 컬럼 조회
- select * from emp where mod(empno, 2) = 1;
문자열 관련 함수
- CHAR: 숫자 → 문자로 변환
- BIT_LENGTH, CHAR_LENGTH, LENGTH: 길이 (인코딩 때문에)
- 영어는 똑같지만 한글은 char_length ≠ length
- select ename, bit_length(ename) BIT, char_length(ename) "CHAR", length(ename) "LENGTH" from emp; select name, bit_length(name), char_length(name), length(name) # length = memory, 한글 한 개는 3개의 메모리 소요 from tstaff;
- LEFT, RIGHT: 길이만큼 왼쪽이나 오른쪽에서 추출
- UPPER, LOWER
- LTRIM, RTRIM, TRIM: 공백 제거
- ex. 구글에서 검색할 때 → 대소문자 구분 안 하고 공백 제거해준다. (ID도 대소문자 구분 X)
- ex. EMP 테이블에서 ENAME이 MILLER인 사원 조회
- select * from emp where lower(ename) = 'miller'; # 오라클은 대소문자 구분하기 때문에 위처럼 써주는게 낫다. # mysql, mariadb는 대소문자 구분x -> where ename = 'miller'라고 해도 나온다.
- substring(컬럼 이름이나 연산식, 시작 위치, 가져올 개수)를 이용해서 부분 문자열 리턴이 가능
- ex. EMP 테이블에서 2월에 입사한 사원의 ENAME과 HIREDATE를 조회 (hiredate: YYYY-MM-DD)
- 프로그래밍 언어는 인덱스 0부터 시작하지만 데이터베이스는 1부터 시작
- select ename, hiredate '입사일' from emp where substring(hiredate, 6, 2) = '02'; ### or where hiredate like '_____02%';
날짜 함수
- 데이터베이스는 날짜를 숫자와 문자 모두로 표현 가능한데 산술 연산도 가능
- 현재 날짜 및 시간을 위한 함수
- CURRENT_DATE( ), CURDATE( )
- CURRENT_TIME( ), CURTIME( )
- NOW( ), LOCALTIME( ), LOCALTIMESTAMP( ) # 보통 timestamp가 더 정확
- CURRENT_TIMESTAMP( )
- 년월일시분초마이크로초를 반환하는 함수도 존재
- YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, MICROSECOND 등
- 날짜 및 시간 함수로 이전 문제 해결
- select ename, hiredate '입사일' from emp where month(hiredate) = 2;
- Maria DB와 MySQL은 일반적인 날짜 형식의 문자열도 날짜로 인식
- 직접 변환하고자 하는 경우는 STR_TO_DATE(날짜 문자열, 서식 문자열)
- 날짜와 INTERVAL을 이용해서 기간형 데이터와 연산 가능
- 날짜 + INTERVAL 숫자 기간(DAY 등)
- select CURRENT_DATE() + interval 2 day;
- 날짜 간의 뺄셈은 DATEDIFF 함수 사용
- SELECT DATEDIFF(CURRENT_DATE(), STR_TO_DATE('1987-05-05', '%Y-%m-%d'));
- 시스템 정보 함수
- USER( ), DATABASE( )
- FOUND_ROWS( )
- ROW_COUNT( )
- 타입 변환 연산자
- DATA TYPE DATETIME: ‘년-월-일 시:분:초’ DATE: ‘년-월-일’ TIME: ‘시:분:초’ CHAR: 문자열 SIGNED: 정수로 부호 사용 가능 UNSIGNED: 정수로 부호 사용 불가 BINARY: binary string
- CAST
- 숫자를 문자로 변환 SELECT CAST(숫자 as CHAR(길이))
- NULL 관련 함수
- IFNULL(데이터1, 데이터2): 데이터1이 NULL이면 데이터2 반환
- select COMM, ifNULL(COMM, 0) + 100 from EMP; # COMM이 NULL 이면 0을 넣고 100 추가해주기 (다른 값들도 다 100 추가 됨)
- NULLIF(데이터1, 데이터2): 두 데이터가 같으면 NULL, 다르면 첫 번째 인자값을 리턴
- COALSCE(데이터 나열): 데이터 중 NULL이 아닌 첫 번째 데이터 리턴
- IF 함수
- IF(연산식, 참일 때 내용, 거짓일 때 내용)
- CASE ~ WHEN ~ ELSE ~ END
- CASE 데이터 WHEN 값 THEN 데이터가 값일 때 내용 … ELSE 일치하는 값이 없을 때 내용 END
다중 행 함수
집계 함수
- 데이터를 그룹화해서 통계를 계산해주는 함수로 숫자나 날짜 데이터에 사용
- GROUP BY 이후에 그룹화가 이루어지므로 HAVING 절이나 SELECT 절에서만 사용 가능
- GROUP BY 절이 존재하는 경우 SELECT 절에서는 GROUP BY에 사용된 컬럼과 집계 함수만 사용 가능 (Maria DB와 MySQL에서는 GROUP BY에 포함되지 않은 컬럼을 SELECT 절에서 사용할 수 있도록 허용한다. 표준 SQL을 따르는 데이터베이스(예: PostgreSQL, Oracle 등)에서는 오류가 발생)
- 종류
- COUNT: 데이터의 개수를 세는 함수 (NULL 제외하고 개수 센다.)
- 값의 존재 유무와 상관없이 모든 행 수를 셀 때는 COUNT(*)
- 특정 컬럼이 NULL이 아닌 것만 셀 때는 COUNT(컬럼명)
- ex. EMP 테이블의 데이터 개수 확인
select count(*) from EMP; - SUM, AVG: NULL 제외하고 합계나 평균 구함
- ex. EMP 테이블의 SAL 컬럼 합계와 평균 확인
select SUM(SAL), ROUND(AVG(SAL)) from EMP; - MAX, MIN, STDDEV(표준편차), VARIANCE(분산)
- COUNT는 모든 데이터가 NULL인 경우 0을 리턴하지만 나머지 함수는 NULL을 리턴
- COUNT: 데이터의 개수를 세는 함수 (NULL 제외하고 개수 센다.)
- GROUP BY
- 컬럼의 값이나 연산의 결과가 동일한 데이터끼리 모아서 처리하는 절
- 이 절에 사용한 컬럼과 집계 함수를 같이 출력해서 보기 좋게 만드는 경우가 많다. (그냥 합계만 출력하면 이게 어떤 컬럼의 합계인지 모르니까)
- 2개 이상의 컬럼으로 묶는 것도 가능하다.
- ex. EMP 테이블에서 DEPTNO로 묶고 JOB별로 묶어서 각 JOB의 SALARY의 합계를 조회
- select DEPTNO, JOB, SUM(SAL) '합계' from EMP GROUP BY DEPTNO, JOB;
- HAVING
- GROUP BY 이후의 조건을 기술하는 절
- HAVING은 GROUP BY로 묶은 그룹별로 조건을 걸기 위해 사용하는 것이고, 보통 COUNT, SUM, AVG 등의 집계함수 결과를 기준으로 조건을 걸 때 사용한다. 일반적으로 집계함수를 쓰는 경우에만 HAVING을 사용하는 게 실용적이다. (안 그럼 그냥 where 써도 되니까)
- ex. EMP 테이블에서 DEPTNO 별로 그룹화 한 후 데이터가 5개 이상인 경우만 DEPTNO와 데이터 개수, 그리고 SAL의 평균을 조회
- select DEPTNO, COUNT(*), ROUND(AVG(SAL)) '평균' from EMP group by DEPTNO having COUNT(*) >= 5;
SELECT - 5. 열을 필터링 한다.
FROM - 1. 사용할 데이터를 테이블의 형식으로 가져옴
WHERE - 2. 행을 필터링 한다.
GROUP BY - 3. 행들을 그룹화 한다. ⇒ max, min 그룹 바이 다음에 쓸 수 있다!!
HAVING - 4. 그룹화 이후의 조건으로 또 필터링 한다.
ORDER BY - 6. 정렬한다.
LIMIT - 7. 행의 개수 설정
- 연습문제
- ex. EMP 테이블에서 인원수, 최대 급여(SAL), 최소 급여, 급여의 합을 계산하여 출력하는 SELECT문 작성
- select COUNT(*) '인원 수', MAX(SAL) '최대 급여', MIN(SAL) '최소 급여', SUM(SAL) '급여 합' from EMP
- ex. EMP 테이블에서 각 업무별(JOB)로 최대 급여(SAL), 최소 급여, 급여의 합을 출력하는 SELECT문 작성
- select JOB, MAX(SAL) 최대급여, MIN(SAL) 최소급여, SUM(SAL) 급여합 # 뛰어쓰기X -> '' 안 써도 됨 from EMP group by JOB # JOB을 같이 출력해주는 것이 좋다.
- ex. EMP 테이블에서 업무별(JOB) 인원수를 구하여 출력하는 SELECT문 작성
- select JOB, COUNT(*) '업무별 인원수' # JOB도 출력하는 게 좋다. from EMP group by JOB
- ex. EMP 테이블에서 최고 급여(SAL)와 최소 급여의 차이는 얼마인가 출력하는 SELECT문 작성
- select MAX(SAL)-MIN(SAL) '최고 급여와 최소 급여의 차' from EMP
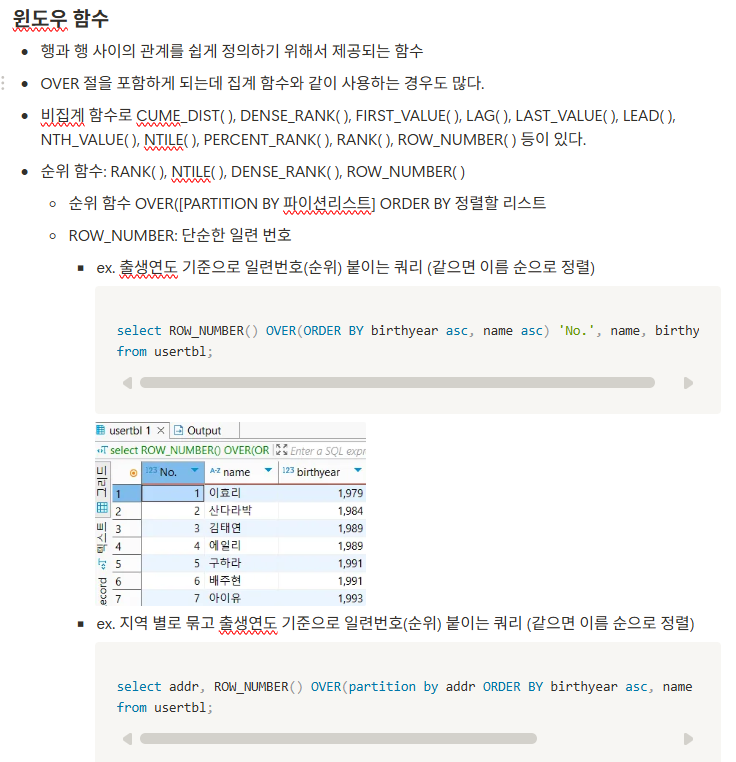
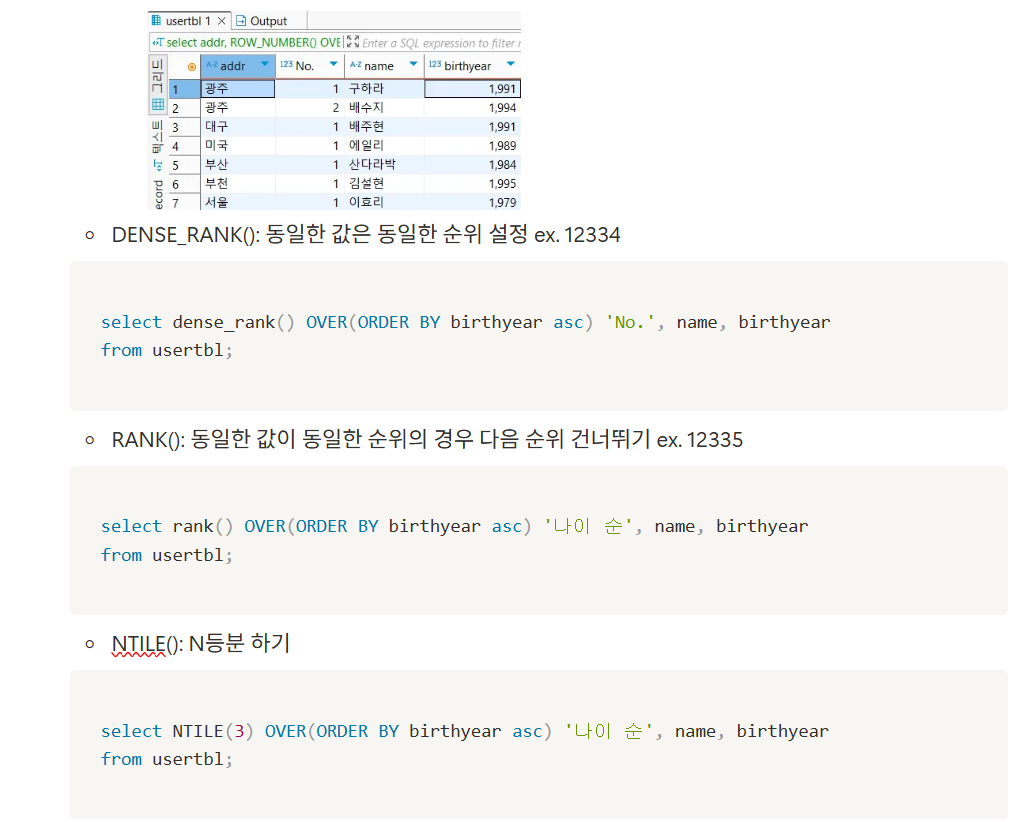


SubQuery와 JOIN
SET 연산
- 2개 이상의 테이블로부터 데이터를 추출하는 방법 중 하나 (나눠서 조회한 걸 합친 거)
- 이 연산자를 이용해서 여러 개의 SELECT 문장을 연결해서 사용 가능
- SELECT 구문 SET operator SELECT 구문 [ORDER BY]
- 주의할 점
- 첫 번째 SELECT 구문과 두 번째 SELECT 구문의 SELECT 절에 기술된 조회된 열의 개수와 자료형이 순서대로 일치해야 한다.
- 컬럼의 헤더는 첫 번째 구문에 기술된 이름이 출력
- ORDER BY는 마지막에 한 번만 기술 가능하고 BLOB, CLOB, BFILE, LONG 타입은 사용할 수 없다.
- 연산자
- UNION: 합집합 - 중복 제거
- UNION ALL: 합집합 - 중복 제거하지 않음
- INTERSECT: 교집합
- EXCEPT: 차집합인데 데이터베이스 종류에 따라 MINUS라고도 한다.
- 합집합 ex. DEPT 테이블의 DEPTNO와 EMP 테이블의 DEPTNO를 합쳐서 조회
SELECT DEPTNO
FROM DEPT
UNION
SELECT DEPTNO
FROM EMP;
- 교집합: INTERSECT 사용
- 차집합: EXCEPT 사용
SELECT DEPTNO
FROM DEPT
EXCEPT
SELECT DEPTNO
FROM EMP;
Sub Query
하나의 SQL 문장 안의 절에 포함된 SQL (안쪽 SQL 먼저 수행)
- Sub Query는 반드시 연산자의 오른쪽에 기재해야 하고 반드시 괄호로 감싸야 한다.
- 분류
- FROM 절에 SELECT 구문을 이용해서 Sub Query를 만들면 이 경우에는 Inline View라고 하고 WHERE 절에 만드는 것을 Sub Query라고 한다.
- 리턴하는 행의 개수에 따라 단일 행 Sub Query와 다중 행 Sub Query로 나눈다.
- 예시
- EMP 테이블에서 ENAME이 MILLER인 사원의 DEPTNO와 같은 값을 갖는 DEPT 테이블의 DNAME을 조회
- SELECT DNAME FROM DEPT WHERE DEPTNO = (SELECT DEPTNO FROM EMP WHERE ENAME='MILLER');
- 단일 행 서브 쿼리: 수행 결과가 오직 하나의 행을 반환하는 서브 쿼리
- 하나의 행을 반환하기 때문에 단일 행 비교 연산자인 =, >, <, ≥, ≤, <> 사용 가능
- ex. tCity 테이블에서 popu가 최대인 도시 이름
- 주의!
SELECT name FROM tCity WHERE popu = max(popu); # group by 순서 때문에 에러 - SELECT name, max(popu) # max(popu)는 값이 1개, name은 값이 여러 개 -> 매칭 안 됨 => 에러 남 FROM tCity;
- 주의!
- SELECT name, popu FROM tCity WHERE popu = (select max(popu) from tCity);
- ex. EMP 테이블에서 sal의 평균보다 더 큰 sal의 값을 갖는 ENAME, SAL을 조회
- SELECT ename, sal FROM emp where sal > avg(sal); # -> 얘도 순서 때문에 에러 ###------------------------------------------------ SELECT ename, sal FROM emp where sal > (select avg(sal) from emp); ## Okay~
- ex. EMP 테이블에서 DEPT 테이블의 LOC가 DALLAS인 사원의 이름(ENAME), 부서 번호(DEPTNO) 출력 (emp 테이블과 dept 테이블은 deptno 컬럼이 같이 존재)
- SELECT ename, deptno FROM emp where deptno = (select deptno from dept where upper(loc) = 'DALLAS');
- 다중 열 서브 쿼리: 서브 쿼리의 결과가 여러 개의 열인 경우
- ex. tStaff 테이블에서 NAME이 안중근인 데이터의 DEPART와 GENDER가 동일한 데이터를 조회
- # 다중 열 서브 쿼리 -> 여러 열을 한 꺼번에 비교 SELECT * FROM tStaff where (depart, gender) = (select depart, gender from tStaff where name='안중근'); # 각 열을 따로따로 비교 SELECT * FROM tStaff where depart = (select depart from tStaff where name='안중근') AND gender = (select gender from tStaff where name='안중근');
- 다중 행 서브 쿼리: 서브 쿼리의 결과가 여러 개의 행인 경우
- 단일 행 연산자 사용하면 에러 발생!
- 다중 행 연산자: IN, ANY, SOME, ALL, EXIST 사용하자 IN: 목록에 포함되면 된다. → GROUP BY가 있으면 리턴 값이 여러 개일 가능성이 높기 때문에 IN 자주 씀 ANY, SOME: 값이 하나라도 일치하면 된다. ALL: 전부 일치해야 한다. EXIST: 하나라도 일치하면 참을 리턴 한다.
- ANY 와 ALL은 MAX 나 MIN 함수로 대체 가능하다.
- ex. EMP 테이블에서 EMPNO, ENAME, SAL, DEPTNO를 조회하는데 SAL이 EMP 테이블의 각 부서(DEPTNO)의 최대 SAL 중 하나와 일치하는 데이터를 조회
- SELECT EMPNO, ENAME, SAL, DEPTNO FROM EMP WHERE SAL IN (SELECT MAX(SAL) FROM EMP GROUP BY DEPTNO); # OR SAL = ANY (SELECT MAX(SAL) FROM EMP GROUP BY DEPTNO); ### 참고 ### <서브 쿼리가 2개 이상의 값을 리턴해서 =로 비교 불가능> SELECT EMPNO, ENAME, SAL, DEPTNO FROM EMP WHERE SAL = (select MAX(SAL) from EMP group by DEPTNO);
- ALL 연산자: 메인 쿼리의 비교 조건이 Sub Query의 검색 결과와 모든 값이 일치하면 True ⇒ 주로 >, < 연산자와 같이 쓰인다.
- ex. DEPTNO가 30인 데이터의 SAL보다 전부 큰 SAL을 가진 데이터의 ENAME과 SAL을 조회
- # DEPTNO가 30인 데이터의 SAL을 조회: 6개의 데이터 조회 SELECT SAL FROM EMP WHERE DEPTNO = 30; # 위에서 검색된 데이터보다 전부 큰 SAL을 가진 데이터를 조회 # 서브 쿼리 결과가 2개 이상 나오기 때문에 SELECT ENAME, SAL FROM EMP WHERE SAL > (SELECT SAL FROM EMP WHERE DEPTNO = 30); # 따라서 SELECT ENAME, SAL FROM EMP WHERE SAL > ALL (SELECT SAL FROM EMP WHERE DEPTNO = 30); # OR 가장 큰 것보다 크면 되니까 SELECT ENAME, SAL FROM EMP WHERE SAL > (SELECT MAX(SAL) FROM EMP WHERE DEPTNO = 30);
- ANY 연산자: 여러 개의 데이터 중 하나만 조건을 만족하면 TRUE
- ex. DEPTNO가 30인 데이터의 SAL보다 하나라도 더 큰 SAL을 가진 데이터의 ENAME과 SAL을 조회
- SELECT ENAME, SAL FROM EMP WHERE SAL > ANY (SELECT SAL FROM EMP WHERE DEPTNO = 30); # OR 가장 작은 것보다 크면 되니까 SELECT ENAME, SAL FROM EMP WHERE SAL > (SELECT MIN(SAL) FROM EMP WHERE DEPTNO = 30);
- ex. EMP 테이블에서 JOB이 SALESMAN인 사원의 최소 SAL보다 SAL이 많은 사원들의 ENAME과 SAL, JOB을 출력하되 영업 사원(SALESMAN)은 출력하지 않도록 작성
- SELECT ENAME, SAL, JOB FROM EMP WHERE SAL > (SELECT MIN(SAL) FROM EMP WHERE JOB = 'SALESMAN') AND JOB <> 'SALESMAN';
- EXIST 연산자: 데이터의 존재 여부를 리턴
- ex. EMP 테이블에서 SAL이 2000이 넘는 사원이 있으면 ENAME과 SAL을 조회 EXIST 뒤의 조건이 참이면 전부 출력
- SELECT ENAME, SAL FROM EMP WHERE EXISTS (SELECT 1 FROM EMP WHERE SAL > 2000);
- 연습 문제
- EMP 테이블에서 ENAME이 BLAKE인 데이터와 같은 부서(DEPTNO)에 있는 모든 사원의 이름(ENAME)과 입사일자(HIREDATE)를 출력하는 SELECT문 작성 (단, BLAKE 제외)
- SELECT ENAME, HIREDATE FROM EMP WHERE DEPTNO IN (SELECT DEPTNO FROM EMP WHERE ENAME = 'BLAKE') AND ENAME <> 'BLAKE'; # OR WHERE DEPTNO = (SELECT DEPTNO FROM EMP WHERE ENAME = 'BLAKE') AND ENAME <> 'BLAKE';
- EMP 테이블에서 평균 급여(SAL) 이상을 받는 모든 종업원에 대해서 종업원 번호(EMPNO)와 이름(ENAME)을 출력하는 SELECT문 작성 (단, 급여가 많은 순으로 출력)
- SELECT EMPNO, ENAME FROM EMP WHERE SAL >= (SELECT AVG(SAL) FROM EMP); ORDER BY SAL DESC;
- EMP 테이블에서 이름(ENAME)에 “T”가 있는 사원이 근무하는 부서에서 근무하는 모든 종업원에 대해 사원 번호(EMPNO), 이름(ENAME), 급여(SAL)를 출력하는 SELECT문 작성 (단, 사원 번호 순으로 작성)
- SELECT EMPNO, ENAME, SAL FROM EMP WHERE DEPTNO IN (SELECT DEPTNO FROM EMP WHERE ENAME LIKE '%T%') ORDER BY EMPNO;
- EMP 테이블에서 DEPT 테이블의 LOC가 DALLAS인 종업원에 대해 이름(ENAME), 업무(JOB), 급여(SAL)를 출력하는 SELECT문을 작성
- SELECT ENAME, JOB, SAL FROM EMP WHERE DEPTNO = (SELECT DEPTNO FROM DEPT WHERE UPPER(LOC) = 'DALLAS'); # DEPTNO : 양쪽에 공통으로 들어있는 컬럼 # 여기서는 돌려주는 값이 1개라 = 써도 되지만 여러 개인 경우 IN 사용!
- EMP 테이블에서 MGR의 이름(ENAME)이 KING인 사원의 이름(ENAME)과 급여(SAL)를 출력하는 SELECT문 작성
- SELECT ENAME, SAL FROM EMP WHERE MGR = (SELECT EMPNO FROM EMP WHERE UPPER(ENAME) = 'KING'); #7839 # 계속 붙어있는지 확인해야 하니까 이 쿼리는 인사 업무에서 굉장히 많이 사용된다. # SELF JOIN
- EMP 테이블에서 월급(SAL)이 DEPTNO가 30인 데이터의 최저 월급보다 높은 사원의 모든 정보를 출력하는 SELECT문 작성
- SELECT * FROM EMP WHERE SAL > (SELECT MIN(SAL) FROM EMP WHERE DEPTNO = 30); # OR WHERE SAL > ANY (SELECT SAL FROM EMP WHERE DEPTNO = 30);
JOIN
2개의 테이블을 가로 방향으로 합치는 연산 (SET은 세로 방향으로 합치는 것)
- 2개 이상의 테이블로부터 여러 개의 컬럼을 추출하고자 할 때 사용
종류
- CROSS JOIN: 2개의 테이블의 모든 조합, Cartesian Product 라고도 함
- EQUI JOIN: 동일한 의미를 갖는 컬럼의 값이 같을 때 조인
- NON EQUI JOIN: 동일한 의미를 갖는 컬럼의 값을 = 이외의 연산자를 이용해서 조인
- OUTER JOIN: 어느 한 쪽 테이블에만 존재하는 데이터도 조인에 참여
- SELF JOIN: 동일한 테이블을 가지고 조인
- SEMI JOIN: 서브 쿼리를 이용해서 조인
테이블 구조
→ EMP 테이블과 DEPT 테이블은 부서 번호인 DEPTNO 컬럼을 모두 가지고 있다. → EMP 테이블: 데이터가 14개, 열이 8개 → DEPT 테이블: 데이터가 4개, 열이 3개
- CROSS JOIN
- 별다른 조인 조건 없이 FROM 절에 2개 테이블 이상을 나열
- 2개 테이블의 모든 조합이 나온다.
- 왠만해서는 하지 말아라! ⇒ 데이터 너무 많이 나와서
SELECT *
FROM EMP, DEPT;
# 56개의 데이터(ROWS), 11개의 열
# 행의 개수는 곱한 것과 같고 열의 개수는 더한 것과 같다.
728x90
반응형
'현대 오토에버 클라우드 스쿨' 카테고리의 다른 글
| 데이터베이스 (2) | 2025.05.20 |
|---|---|
| 데이터베이스 (1) | 2025.05.20 |
| 데이터베이스 (2) | 2025.05.20 |
| Web Programming (0) | 2025.05.20 |
| 파이썬 프로그래밍 (0) | 2025.05.20 |
'현대 오토에버 클라우드 스쿨' Related Articles
more

