

Gom3rye
데이터베이스 본문
제약 조건
1. 제약 조건 확인
select *
from INFORMATION_SCHEMA.TABLE_CONSTRAINTS;
2. 제약 조건 수정
ALTER TABLE 테이블이름 MODIFY 컬럼이름 자료형 제약조건;
3. 제약 조건 추가
ALTER TABLE 테이블이름 ADD 제약조건(컬럼이름)
4. 제약 조건 삭제
ALTER TABLE 테이블이름 DROP CONSTRAINT **제약조건이름**
- 이 경우 제약 조건 이름을 사용해서 삭제를 수행하는데 제약 조건을 만들 때 이름을 설정하지 않으면 Maria DB가 임의로 제약 조건 이름을 설정한다.
- 제약 조건을 만들 때 Constraint 제약조건이름을 추가해서 만들면 제약 조건 이름을 원하는 대로 만들 수 있다. → 대부분 기본키는 PK 외래키는 FK 체크 제약조건은 CK등의 약자를 추가하는 경우가 많다.
5. 기본값
- 필드 값을 지정하지 않았을 때 자동으로 입력되는 값
- DEFAULT 라는 키워드와 함께 지정
- 기본값을 입력하고자 할 때는 컬럼을 제외하고 삽입하거나 DEFAULT로 설정하면 된다.
ex. tCityDefault 라는 테이블 생성 name: 고정크기 문자 10개 기본키 area: 정수, null 허용 popu: 정수, null 허용 metro: 고정크기 한 글자인데 기본값은 n이고 null 허용 x region: 고정크기 문자 6개로 구성하는데 null 허용 x <주의>
- utf8 : 3 byte
- utf8 mb4 : 4 byte → 이모티콘 가능 ⇒ 문자 보낼 때나 게시글 만들 때 인코딩이 이렇게 되어야 한다.
- Not null은 테이블 제약조건으로는 만들 수 없다.
create table tCityDefault(
name char(10)
area int,
popu int,
metro char(1) default 'n' not null,
region char(6) not null
constraint pk_tCity primary key(name)); # 테이블 제약조건으로 만들기
# 또는
create table tCityDefault(
name char(10) primary key,
area int,
popu int,
metro char(1) default 'n' not null,
region char(6) not null);

6. auto_increment
→ 컬럼의 자료형 옆에 기재하면 되는데 기본적으로 자료형은 정수
→ 테이블을 만들 때 기본값을 설정할 수 있고 나중에 변경할 수 있다.
→ 테이블 당 1개만 생성 가능
→ Maria DB에서는 일련번호를 컬럼에 설정해도 직접 값 입력이 가능하다.
→ auto_increment 가 되려면 primary key나 unique 제약 조건을 설정해줘야 한다. (유일무이하니까)
→ 지웠다가 추가하더라도 일련번호는 되돌아가지 않는다. → 이것때문에 AUTO_INCREMENT 안 쓰는 사람도 있다.
create table tSale(
saleno int auto_increment primary key,
customer varchar(10)
);
insert into tSale(customer) values('군계');
insert into tSale(customer) values('쥬니');
insert into tSale values(3, 'henry'); # auto_increment 설정되어 있으니까 직접 설정은 조심해야 한다.
delete from tSale where CUSTOMER='henry';
insert into tSale(customer) values('지원'); # 지워진 3이 아니라 4가 된다.
select * from tSale;
→ 일련번호 수정
ALTER TABLE 테이블이름 AUTO_INCREMENT = 시작값;

- DBMS 종류마다 일련번호 생성 방법이 다름
- ORACLE: Sequence
- Maria DB: Auto_increment → 일련번호는 삭제하면 복구 되지 않음 ⇒ 가장 큰 번호 + 1로 규칙을 매기면 실수하지 않을 수 있다. by 프로그래밍 언어
DML (데이터 조작 언어)
- 이론에서는 SELECT, INSERT, DELETE, UPDATE 4가지를 DML로 보지만, 실무에서는 SELECT를 DQL(Data Query Lang)로 분류한다. (select 빼고 3개는 모두 db에 변경이 되니까)
- select는 조회만 하는 거니까 동시에 할 수 있지만, insert, delete, update는 디비에 변경을 가하는 언어니까 동시에 할 수 없음
- 조회: NoSQL (Mongo DB)
- 삽입, 삭제, 갱신: RDBMS (조회는 느림)
데이터 삽입
INSERT INTO 테이블이름(컬럼 목록) VALUES(값을 나열);
insert into tcity(name, area, popu, metro, region) values('하와이', 123, 333, 'y', '미국');
- 모든 컬럼에 값을 대입할 때는 컬럼 목록을 생략하고 values에 순서대로 값을 나열해도 된다.
- INSERT INTO tCity VALUES('괌', 3324, 158, 'n', '미국');
- 확장 insert : 여러 개의 데이터를 한꺼번에 삽입하는 것, values 다음에 여러 개의 괄호를 나열하면 된다. ⇒ 샘플 데이터 만들 때 종종 사용
- insert into tcity(name, area, popu, metro, region) values('서울', 605, 974, 'y', '특별시'), ('부산', 725, 542, 'y', '광역시'), ('제주', 237, 333, 'n', '특별시');
- 다른 테이블로부터 조회한 목록을 삽입
- insert into tStaff(name, depart, gender, joindate, grade, salary, score) select name, region, metro, '20110629', '신입', area, popu from tCity where region='경기';
- select 구문을 이용해서 테이블 생성 가능
- 구조만 복사하고자 한다면 where절에 거짓인 조건 기술하면 된다.
- -- dept 테이블의 모든 데이터를 복사해서 새로운 테이블 생성 create table deptcopy as select * from dept; select * from deptcopy; -- emp 테이블과 구조가 동일한 테이블만 생성 (자료는 없다.) create table empcopy as select * from emp where 0 = 1; select * from empcopy;
- 여러 개의 INSERT 구문을 수행할 때 INSERT와 INTO 사이에 IGNORE를 추가하면 에러가 발생하더라도 다음 스크립트를 수행한다.
- insert ignore into memberTBL values('adam', '군계', '목표'); -- 순차적인 데이터를 넣는 게 아니라면 ignore 넣어주는 거 추천
데이터 삭제
- 조건이 없으면 모든 데이터 삭제
delete from tCity where name = '부산';
데이터 수정
update 테이블이름 set 컬럼이름 = 새로운 값
[where 조건];
ex. tCity 테이블에서 name이 서울인 데이터의 popu는 1000으로 region은 충청으로 수정
update tCity set popu = 1000, region = '충청'
where name = '서울';
- dept 테이블에서 deptno가 20인 데이터의 loc(dallas)를 deptno가 40인 데이터의 loc(boston)으로 수정해라. ⇒ self query 이용
- update dept set loc = (select loc from dept where deptno = 40) where deptno = 20;
- emp 테이블에서 dname이 sales인 데이터를 전부 삭제 (emp.deptno = dept.deptno, dname은 dept테이블에 존재) ⇒ self query 이용
- delete from emp where deptno = (select deptno from dept where dname = 'sales');
TCL
Transaction
한 번에 수행되어야 하는 논리적인 작업 처리 단위
- 물리적인 작업 처리 단위: sql 문장
- 데이터베이스에서 작업의 단위로 Transaction이란 개념을 도입한 이유는 데이터의 일관성을 유지하면서 안정적으로 데이터를 복구시키기 위해서 (양쪽 다 거래가 완료되었을 때 처리해줘야 한다.)
Transaction의 4가지 성질
- 원자성(Atomicity): All or Nothing - 하나의 트랜잭션은 전부 처리하던지 하나도 처리를 하지 않아야 한다.
- 일관성(Consistency): 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 상태를 유지해야 한다.
- 독립성(Isolation): 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것
- 영속성(Durability): 성공적으로 수행된 트랜잭션은 영원히 반영되어야 한다.
트랜잭션 처리 방법
- Auto Commit: 하나의 SQL이 성공적으로 수행되면 자동으로 commit
- Manual Commit: DML의 경우에는 사용자가 직접 commit을 해야만 commit되는 방식
Transaction Control Language
- COMMIT: 현재 트랜잭션을 완료
-- 데이터 추가
insert into dept values(50, '총무', '서울');
-- 작업 완료
commit;
-- 작업 취소 -> x
rollback;
-- 이전 작업이 취소되었는지 확인
select * from dept; # 이미 커밋을 해서 변경 내역을 반영시켰기 때문에 50 데이터 추가되었다.
- SavePoint: 중간 저장점을 만들기
-- 데이터 추가
insert into dept values(70, '비서', '파주');
-- 저장점 생성
savepoint s1;
-- 데이터 추가
insert into dept values(80, '회계', '포천');
-- 현재 상태 확인
select * from dept;
-- s1으로 롤백-> 70 넣은 후로 돌아감
# (중간에 rollback 하면 commit을 하지 않았기 때문에 70을 넣기 전으로 돌어가고)
rollback to s1;
select * from dept;
- Rollback: 현재 트랜잭션을 취소하거나 중간 저장점으로 돌아가는 명령
-- 데이터 삭제
delete from emp where ename = 'SCOTT';
-- 확인
select * from emp;
-- 작업 취소
rollback;
-- 이전 작업이 취소되었는지 확인
select * from emp;
자동으로 commit 되거나 rollback 되는 경우
- 자동으로 commit
⇒ DML 이외의 DDL이나 DCL 명령이 성공한 경우
⇒ 접속이 정상 종료되는 경우 (로그아웃→ commit된다.)
- 자동으로 rollback
⇒ 비정상적으로 종료되는 경우 (게임 서버 종료되기 전에 메시지 준다.)
-- 테이블 삭제 (**drop, truncate 는 ddl 문장이므로 성공하면 자동으로 commit 된다.**)
drop table tstaff;
-- 작업 취소
rollback;
-- 확인:
select * from tstaff; # 자동 커밋된 후 rollback 했으므로 삭제 되돌릴 수 없음
Mongo DB
특징
- 2007년 10gen에서 자바 기반의 클라우드 플랫폼을 위한 컴포넌트로 개발
- 크로스 플랫폼 도큐먼트 지향 NoSQL 데이터베이스 시스템
- 스키마 생성 없이 데이터 저장이 가능하다. → 남이 만든 거 쓰면 알아보기 어렵다. 정형 → 데이터 표현: class → Instance ⇒ RDBMS: SQL (name: 김~, age: 9) Map(dict) → Instance ⇒ NoSQL
- 명령어 입력 터미널은 자바스크립트 인터프리터를 제공하고 내부는 C++로 동작
- 확장성이 뛰어나고 성능 우수
- 저장 프로시저나 SQL 대신 자바스크립트 함수 형태로 사용하기 때문에 개발자에게 친숙하다.
- 복제와 샤딩(자주 사용하는 데이터와 아닌 데이터를 쪼개는 것)을 이용한 쉽고 빠른 분산 컴퓨팅 환경을 구성할 수 있다.
외부 접속 허용
- bindIp : 0.0.0.0 으로 설정해야 한다. → 모든 ip
- bindIp : 127.0.0.1 이면 내부에서만 접근 가능
RDBMS 와 용어 비교
RDBMS → Mongo DB
- Database → Database
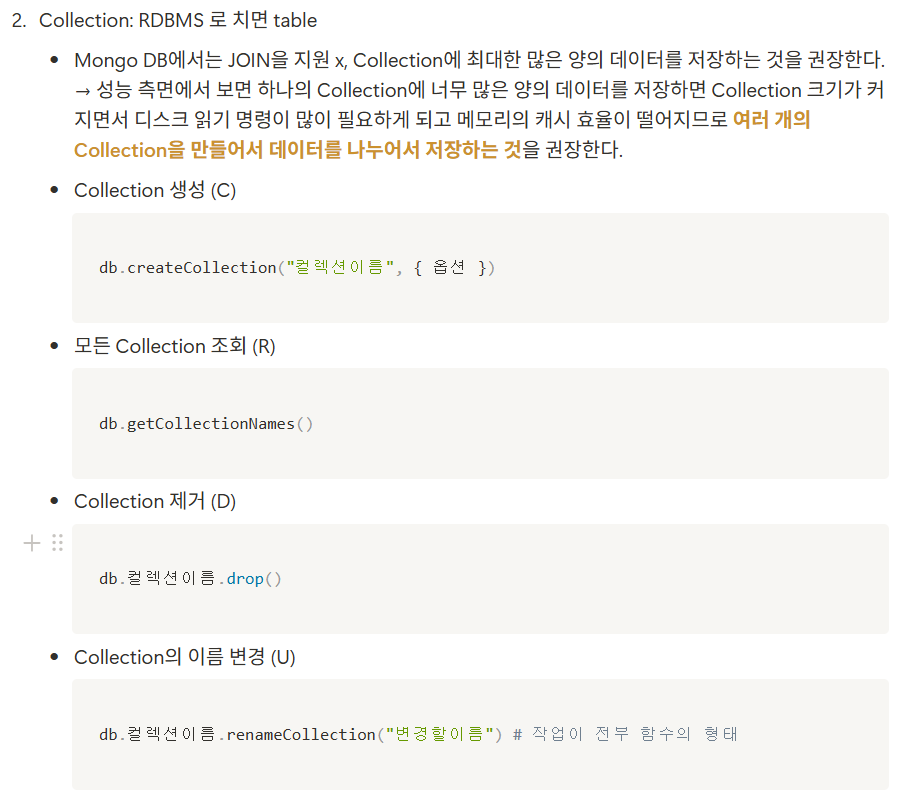
- Table → Collection
- Row → Document
- Column → Field
- Index → Index
- Join → Embedding & Linking
- 조회의 결과는 Row 집합 → Cursor (포인트 형태)
데이터 형식
JSON (Binary JSON - JavaScript Object Notation)
JSON 표기법
- { }: 객체
- 속성: 값 의 형태로 객체 안에 데이터를 표시
- [ ]: 배열
- 속성과 데이터들의 구분은 ,
객체 안에 배열이 있을 수 있고 배열 안에 객체가 존재할 수 있다.
{ name: "kim", score: [10,20,30,40]
phone: [{main:"011"}, {sub:"010"}] }
배열만 존재하는 경우는 없다.
- 장점
- Light Weight: 가벼움
- 조회가 빠름
- 기본 데이터 타입으로 C언어의 Primitive 타입을 사용하므로 빠름
데이터 타입
- Double
- String
- Object
- Array
- Binary Data
- ObjectID: 12Byte Binary Data로 데이터를 구분하기 위한 _id 필드의 데이터
- Boolean
- Date, Timestamp
- Null
- Regular Expression (정규 표현식)

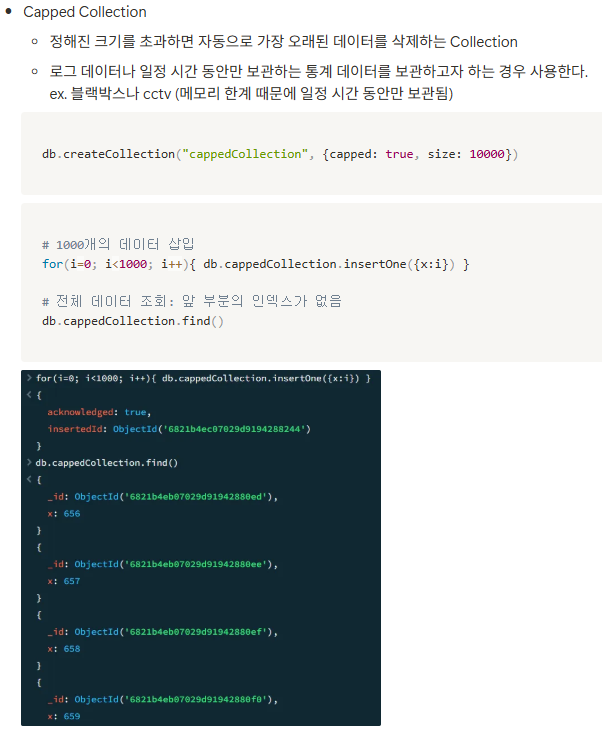
'현대 오토에버 클라우드 스쿨' 카테고리의 다른 글
| 파이썬과 데이터베이스 연동 (1) | 2025.05.20 |
|---|---|
| Mongo DB (0) | 2025.05.20 |
| 데이터베이스 (1) | 2025.05.20 |
| 데이터베이스 (0) | 2025.05.20 |
| 데이터베이스 (1) | 2025.05.20 |



