

Gom3rye
Mongo DB 본문
Mongo DB
- NoSQL
- 읽기에 특화: JOIN이 없음
- Linking: 참조를 기억시킴(몽고는 프로그래밍 언어랑 비슷하니까)
- 단점: 뭐 하나를 지우려고 하면 그 참조도 지워야 한다. ⇒ 삽입과 삭제에는 약하고 삽입과 삭제가 빈번하면 느려진다.
- Embedding: 다른 문서의 데이터를 중첩 구조로 하위 문서로 포함시킴
- 단점: 하나의 레코드의 길이가 너무 길어져서 보기가 어렵고 사이즈가 크면 속도가 느려진다.
- 읽기와 쓰기의 비율이 동일할 가능성이 별로 없다.)
- 사용자 요청은 MySQL(RDBMS)에 기록 (쓰기)
- 변경된 데이터를 Message Queue (Kafka, RabbitMQ 등)에 Publish
- MongoDB가 그 메시지를 Subscribe해서 읽기용 데이터로 저장 (Read Model 구축)
- 프론트는 MongoDB에서 빠르게 조회
- Linking: 참조를 기억시킴(몽고는 프로그래밍 언어랑 비슷하니까)
- 🔸 읽기/쓰기 분리 설계한 사용 예시:
fk를 설정하지 않아도 합칠 수 있지만 없으면 full table 스캔을 해야 한다. (fk는 pk이거나 unique 해야 하니까 하나만 존재함 → 한 번 찾으면 더 이상 찾을 필요가 없다. (full table scan 하지 않아도 된다.))
- MongoDB, MySQL - 한 db에 여러 사용자 존재 (db가 유저보다 큰 개념 → 항상 use {db이름}으로 시작)
- Oracle - 한 유저에 db 존재 (유저가 db보다 큰 개념)
데이터베이스 상태 조회
db.getCollectionInfos() # 현재 데이터베이스의 Collection들의 정보 조회


Collection의 상태 조회
- Collection 목록 조회
show collections # cappedCollection
- Collection 정보 리턴
db.컬렉션이름.stats() # db.cappedCollection.stats()
- 지연 시간 확인
db.컬렉션이름.latencyStats() # db.cappedCollection.latencyStats()
- Collection 크기 확인
db.컬렉션이름.storageSize() # db.cappedCollection.storageSize() result: 24576
- 인덱스 크기 확인
db.컬렉션이름.totalIndexSize() # db.cappedCollection.totalIndexSize() result: 20480
- 전체 크기 확인 (collection 크기 + 인덱스 크기)
db.컬렉션이름.totalSize() # db.cappedCollection.totalSize() result: 45056
Collection의 전체 데이터 조회
db.컬렉션이름.**find()** # db.cappedCollection.find()
Document 생성 (데이터 삽입)
특징
- 단일 Collection을 대상으로 수행한다.
- 단일 Document 레벨에서 원자적으로 수행된다. (하나씩 된다.)
- JSON 표현식으로 데이터를 만들어서 삽입한다.
- Collection을 만들고 삽입해도 되고 Collection이 없는 경우 처음 삽입하면 Collection이 만들어진다.
- Document를 만들 때 _id라는 key를 만들지 않고 생성하면 자동으로 _id라는 key가 생성되면서 ObjectId를 부여해서 데이터를 구분한다.
- 삽입하는 함수: insert(deprecated 되었다.), save, insertOne, insertMany
- insert는 동일한 _id를 갖는 데이터를 추가하면 ERROR, but save는 데이터를 수정한다.
Insert()
일반 객체 삽입
db.users.insert({name:"adam", age:25, gender:'man'}) # users 컬렌션 만듬
객체 안에 객체와 배열이 존재하는 경우
db.inventory.insert({item:"ABC1", details:{model: "14Q3", manufacture: "xyz Company"},
stock: [{size: "s", qty: 25}, {size: "m", qty: 50}],
category: "clothing"})
- → users, inventory 컬렉션들 없었는데 show collections 해보면 생긴 것을 확인할 수 있다. → acknowledged: true 나오면 명령 성공한 것
여러 개의 데이터를 한꺼번에 삽입한 경우
- [ ]를 이용해서 배열 안의 데이터들을 쪼개서 넣음
db.users.insert([ {name: "군계"}, {name: "쥬니"} ])
# 또는
db.users.insertMany([
{ name: "군계", age: 25 },
{ name: "쥬니", age: 30 },
{ name: "Charlie", age: 22 }
])
- insert 함수의 두 번째 매개변수는 생략 가능한데 ordered 옵션을 설정해서 첫 번째 매개변수의 데이터가 배열일 때 싱글 스레드를 이용할지 멀티 스레드를 이용할지를 설정할 수 있다. 이때 true 옵션을 설정하면 싱글 스레드, false를 설정하면 멀티 스레드
- 싱글 스레드 사용: 중간에 에러가 발생하면 뒤의 데이터는 삽입되지 않는다.
- 멀티 스레드 사용: 중간에 에러가 발생하더라도 뒤의 데이터 삽입된다.
ex. sample이라는 컬렉션을 생성하는데 name을 index로 설정 (인덱스를 만들고 unique 속성 설정 가능)
db.sample.createIndex({name: 1}, {unique: true})

- sample 데이터 생성
db.sample.insert({name: "군계"})
- 싱글 스레드 사용해서 여러 개의 데이터 삽입
db.sample.insert([{name: "쥬니"}, {name: "군계"}, {name: "헨리"}], {ordered: true})
# {ordered: true}: 명시적으로 싱글 스레드 사용하고 싶으면 사용
- 쥬니는 정상적으로 삽입되지만 군계는 중복된 키 사용으로 에러가 발생해서 군계 이후 데이터는 삽입되지 않는다. (스레드 중단)
- 멀티 스레드 사용해서 여러 개의 데이터 삽입
db.sample.insert([{name: "쥬니"}, {name: "군계"}, {name: "헨리"}], {ordered: false})
- db.sample.find() 로 데이터를 조회하면 쥬니와 군계가 중복돼서 키 에러가 발생하지만 헨리 데이터는 다른 스레드로 삽입하기 때문에 삽입 성공
⇒ MongoDB에서 삽입할 때 옵션을 설정하는데 없는 옵션을 설정해도 에러가 발생하지 않는다.
이유는 모든 옵션을 읽어서 적용하는 게 아니라 필요한 옵션만 추출해서 적용하기 때문
db.sample.insert({name: "비앙카"}, {noption: true})
ObjectId
- RDBMS 에서는 Sequence나 auto_increment 같은 옵션이나 객체를 이용해서 일련번호를 생성해서 사용
- MongoDB 에서는 12 byte로 구성된 ObjectId를 제공
- 컬렉션을 만들면 _id라는 속성으로 ObjectId를 생성해서 할당하는 방식으로 일련번호를 부여
- new ObjectId()를 이용해서 직접 생성 가능
ex. 직접 생성해서 만드는 방법
let newId = new ObjectId()
db.sample.insert({_id: newId, name: "user01"})
# 확인은 db.sample.find()로!
insertOne()
- 하나의 데이터를 삽입하고자 할 때 사용하는 함수
- 데이터를 삽입하면 성공 여부와 ObjectId를 리턴
db.user.insertOne({username: "karoid", password: 1111})
writeConcern
- 삽입, 삭제, 갱신하는 명령은 writeConcern 옵션을 제공하는데 이 옵션은 데이터 손실을 방지하기 위한 옵션이다.
- 일반적으로 삽입, 삭제, 갱신 명령은 저장 장치에 바로 명령을 수행하는 것이 아니라 메모리에 작업을 수행한 후 나중에 저장 장치에 반영을 하는데 이런 경우 데이터베이스에 갑자기 문제가 생기면 메모리에만 저장된 데이터를 잃어버릴 수 있기 때문에 이를 방지하기 위한 옵션 → 디스크가 여러 개일 때 유용한 명령
- 구독해서 여러 디스크들끼리 싱크 맞출 수 있게 해준다.
insertMany()
- 여러 개의 데이터를 삽입하고자 하는 경우 사용
db.컬렉션이름.insertMany([데이터 나열], {writeConvern: { }, ordered: <boolean> })
db.user.insertMany([
{username: "John", password: 4321},
{username: "Kyla", password: 4221},
{username: "Mark", password: 5321}
])

데이터 조회
단일 Collection에서만 Document를 선택할 수 있다. (JOIN 없으니까)
Cursor: 결과를 가지고 하나씩 접근할 수 있도록 해주는 객체
find()
find(query, projection)
- selection: 데이터를 조회하기 위한 조건 (MySQL에서 where절)
- projection: 컬럼 단위 추출 (MySQL에서 select절)
- Cursor가 리턴된다.
- 컬렉션의 전체 데이터 조회
db.컬렉션이름.find()
db.users.find()
db.containerBox.find({},{_id:false}) # id 안 보이고 실제 데이터만 보이도록
(MongoDB Compass를 이용하면 더 쉽게 collection을 만들어서 json 파일들을 넣을 수 있다.)
- query
- 원하는 조건을 작성하는 옵션
- ex. containerBox 라는 컬렉션에서 name이 가위이고 size가 30인 데이터 조회
- db.containerBox.find({name: "가위", size: 30})
샘플 데이터 삽입
db.containerBox.insertMany([
{name: "bear", weight: 60, category: "animal"},
{name: "bear", weight: 10, category: "animal"},
{name: "cat", weight: 3, category: "animal"},
{name: "phone", weight: 1, category: "electronic"}
])
category가 animal이고 name이 bear 인 데이터 조회
db.containerBox.find({name: "bear", category: "animal"})
. 연산자
객체 안의 속성을 불러올 때 사용한다.
let myvar = {hello: "world"}
myvar.hello # world
- 객체 안에 존재하는 객체의 속성을 사용하고자 하는 경우 {name: {firstName: "karoid", lastName: "Jeong"}} ex. name 안에 있는 firstName의 값이 karoid 인 데이터를 조회
- db.컬렉션이름.find({ "name.firstName": "karoid" })
- 배열 안의 데이터 조회
db.컬렉션이름.find({ "numbers.0": 52 }) - {numbers: [101, 32, 21, 11]} {numbers: [64, 32, 21, 11]} {numbers: [52, 32, 21, 11]} 배열 안의 첫 번째 요소 값이 52인 데이터 조회 ⇒ .0
- projection
- 원하는 컬럼을 추출하는 것
- find 두 번째 옵션으로 설정
- true나 1로 설정하면 출력되고 false나 0으로 설정하면 조회되지 않는다.
- {컬럼이름: <Boolean>, 컬럼이름: <Boolean> ...}
- containerBox 컬렉션에서 name을 조회
- db.containerBox.find({}, {name: true}) # {}는 query 부분 → "조건 없이 전체 문서를 가져와라" 라는 의미 # if _id 안 나오고 name만 나오도록 찾고 싶다면 db.containerBox.find({}, {_id: 0, name: true})

Cursor
질의에 대한 포인터
- Mongo DB는 find의 결과로 커서를 리턴한다.
- find의 결과를 저장하고 그 저장한 커서를 이용해서 next 함수를 호출하면 다음 데이터가 호출되고 hasNext 함수를 호출하면 다음 데이터의 존재 여부를 리턴한다.
- cursor.next() 로 불러오면 메모리를 절약할 수 있다. (하나씩 불러오니까)
db.cappedCollection.find() # 쫘르륵 보이고
let cursor = db.cappedCollection.find() # 아무 일도 안 일어난 것처럼 보인다.

Document 수정
replaceOne()
db.컬렉션이름.replaceOne(
<query>,
<replacement>,
{
upsert: <boolean>,
collation: <document>
}
)
- query: 수정할 데이터를 추출
- replacement: 수정할 내용
- upsert: 조건에 맞는 데이터가 없을 때 추가 여부
- collation: 악센트나 대소문자 관계에 대한 순서를 설정
db.user.replaceOne(
{username: "karoid"},
{username: "Karoid", status: "Sleep", points: 100, password: 2222})
db.user.find({username:"Karoid"}) # 로 확인해보기
- upsert 옵션
db.myCollection.find() # 없는 거 확인함
db.myCollection.replaceOne(
{item: "abc123"},
{item: "abc123", status: "P", points: 100},
{upsert: true}) # {upsert: true}가 없으면 매치된 데이터가 없기 때문에 find를 해도 아무런 데이터가 나오지 않음
# upsert를 하면 없는 경우 새로 만들어준다.

updateOne()
조건에 맞는 데이터가 여러 개더라도 1개만 수정
→ 이 함수들은 $set 연산자를 이용해서 수정할 내용을 작성해야 한다.
ex. 아무 조건 없이 첫 번째 문서를 선택해서 username 바꾸기
db.user.updateOne({}, { $set: { username: "Modified" } })
구문 의미
| replaceOne({}, { ... }) | ✅ 전체 문서를 새 객체로 교체 |
| updateOne({}, { $set: {...} }) | ✅ 필드 일부만 수정 |
updateMany()
db.containerBox.updateMany(
{name: "bear"},
{$set: {name: "teddy bear", category: "toy"}})
document 수정 연산자
$currentDate: 오늘 날짜로 수정
$inc: 증가시켜주는 연산자
$min: 최소값으로 변경시켜주는 연산자 (그 반대 max도 있다.)
$mul: 곱해주는 연산자
$rename: 컬럼의 이름을 수정해주는 연산자
$setOnInsert: 값을 한꺼번에 설정하는 연산자
$unset: 컬럼을 제거
- ex. 배열 데이터 생성
- db.character.insertMany([ {name: 'x', inventory: ['pen', 'cloth', 'pen']}, {name: 'y', inventory: ['book', 'cloth']}, {name: 'z', inventory: ['wood', 'pen']} ])
- inventory 컬럼에 있는 pen을 pencil로 수정 → (배열의 데이터 수정하는 거라 어려움)
- db.character.updateMany( {}, {$set: {"inventory.$[penElem]": "pencil"}}, {arrayFilters: [{penElem: "pen"}]} )
- pencil을 pen으로 수정 ⇒ 배열에서 첫 번째 요소만 변경
- db.character.updateMany( {inventory: "pencil"}, {$set: {"inventory.$": "pen"}} )

update 파라미터와 연산자
종류
- $addToSet: 배열 안에 해당 값이 없다면 추가하고 있다면 추가하지 않는다.
- $pop: 배열 안의 첫 번째 혹은 마지막 요소를 삭제
- $pull: 쿼리에 해당하는 요소 하나를 제거한다.
- $push: 해당 요소를 배열에 추가
- $pulAll: 해당하는 값을 가진 요소 전부를 제거한다.
Document 삭제
deleteOne(<query>, {옵션})
deleteMany(<query>, {옵션})
db.character.deleteOne({})
db.character.deleteMany({})
- 조건을 주고 싶을 때
- db.containerBox.deleteMany({category: "animal"})
Python과 Mongo DB 연동
- 필요한 패키지 설치: pymongo
- pip install pymongo # (만약 배포도 생각한다면 가상 환경 만들고 그 안에서 수행)
- 서버와 데이터베이스 연결
- 서버 연결
- 변수 = pymongo.MongoClient(서버IP, 포트 번호)
- 데이터베이스 연결
- 변수 = 서버변수.데이터베이스이름 (이때 데이터베이스가 없으면 새로 생성됨)
- 컬렉션 연결
- 변수 = 데이터베이스변수.컬렉션이름 (컬렉션이 없으면 새로 생성됨 but, 데이터가 들어오면 그때 실제로 생성되는 것 ex. 연결 ↔ 복사본 ↔ 원본)
from pymongo import MongoClient # 데이터베이스 서버 연결 con = MongoClient('127.0.0.1', 27017) # 데이터베이스 연결 db = con.adam # collection 연결 (만들기) users = db.users; - 서버 연결
- 데이터 삽입
컬렉션변수.insert_one 또는 insert_many 사용
doc1 = {'empno': 1001, 'name': '군계'} # 키를 문자열로 써야 한다.
doc2 = {'empno': 1002, 'name': '쥬니'}
doc3 = {'empno': 1003, 'name': '초콜릿'}
doc4 = {'empno': 1004, 'name': '헨리'}
doc5 = {'empno': 1005, 'name': '헨리'}
users.insert_one(doc1)
users.insert_one(doc2)
users.insert_many([doc3, doc4, doc5]) # many를 할 땐 배열로!
# print(users.count_documents({})) -> 5 (데이터 개수 확인)
→ 다시 MongoDB Compass로 가서 use adam, db.users.find() 해보면 데이터가 잘 들어간 것을 확인할 수 있다.
- 데이터 조회 (이건 똑같다.)
- find() 와 find_one()
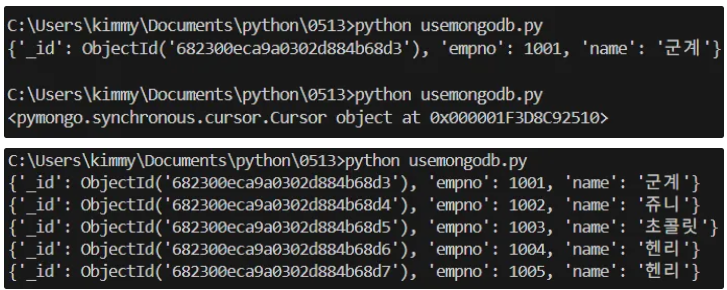
print(users.find_one({})) # 하나만 출력됨
print(users.find())
cursor = users.find()
for data in cursor:
print(data)
'현대 오토에버 클라우드 스쿨' 카테고리의 다른 글
| Linux (0) | 2025.05.20 |
|---|---|
| 파이썬과 데이터베이스 연동 (1) | 2025.05.20 |
| 데이터베이스 (2) | 2025.05.20 |
| 데이터베이스 (1) | 2025.05.20 |
| 데이터베이스 (0) | 2025.05.20 |


